BERT
BERT(Bidirectional Encoder Representations from Transformers)는 Google이 2018년에 발표한 사전학습 기반 자연어처리(NLP) 모델입니다. Devlin et al. (2019) Transformer 아키텍처를 기반으로 하며, 특히 양방향성(Bidirectional)을 활용한 점이 혁신적입니다. BERT는 여러 자연어 처리 태스크에서 SOTA(State-of-the-Art)를 기록하며 NLP 패러다임을 바꾼 중요한 모델입니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import transformersHuggingface BERT¶
model_id = 'google-bert/bert-base-multilingual-cased'
tokenizer = transformers.BertTokenizerFast.from_pretrained(model_id)
# 실제 어텐션 텐서를 보기 위해 output_attentions=True 설정
bert = transformers.BertModel.from_pretrained(model_id, output_attentions=True)Skipping import of cpp extensions due to incompatible torch version 2.8.0+cu128 for torchao version 0.15.0 Please see https://github.com/pytorch/ao/issues/2919 for more info
print(f'어휘수: {tokenizer.vocab_size:,}')
print(bert)어휘수: 119,547
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(119547, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
토큰화¶
예문 = '배 타고 배 먹으니 배 부르다.'
형태소목록 = tokenizer.tokenize(예문, add_special_tokens=True)
정수시퀀스 = tokenizer(예문, return_tensors='pt', add_special_tokens=True)
pd.DataFrame({
'정수토큰': 정수시퀀스['input_ids'].squeeze().tolist(),
'형태소': 형태소목록})Loading...
임베딩¶
단어임베딩계층 = bert.embeddings.word_embeddings
단어임베딩행렬 = 단어임베딩계층.weight.detach().cpu().numpy()
print(f'단어 임베딩 행렬: {단어임베딩행렬.shape}') # (어휘수, 임베딩차원)단어 임베딩 행렬: (119547, 768)
단어 = '배'
정수토큰 = tokenizer.convert_tokens_to_ids(단어)
print(f"단어 '{단어}'의 정수 토큰: {정수토큰}")
print(f'임베딩 벡터: {단어임베딩행렬[정수토큰][:10].round(3)} ...')단어 '배'의 정수 토큰: 9330
임베딩 벡터: [-0.03 -0.078 0.005 -0.042 0.058 -0.062 -0.034 0.013 -0.022 -0.045] ...
모형 출력¶
model_inputs = tokenizer(예문, return_tensors='pt')
print(model_inputs['input_ids'].shape)
with torch.no_grad():
model_outputs = bert(**model_inputs)
print(type(model_outputs))
print(model_outputs.keys())
print(model_outputs.last_hidden_state.shape)torch.Size([1, 14])
<class 'transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions'>
odict_keys(['last_hidden_state', 'pooler_output', 'attentions'])
torch.Size([1, 14, 768])
벡터 유사도¶
from sklearn.metrics.pairwise import cosine_similarity
# 단어 '배'에 대한 출력 벡터
단어위치 = torch.where(정수시퀀스['input_ids'].squeeze() == 정수토큰)[0]
# 선별 벡터들의 유사도 계산
단어출력벡터 = model_outputs.last_hidden_state[0, 단어위치, :].numpy()
# 유사도 계산
유사도행렬 = cosine_similarity(단어출력벡터, 단어출력벡터)
pd.DataFrame(유사도행렬, index=[f'배{i+1}' for i in range(len(단어위치))]).round(3)
Loading...
어텐션¶
# 어텐션 계산 방식 설명 및 구현
print("=" * 70)
print("Transformer 어텐션 메커니즘 계산 방식")
print("=" * 70)
# 1단계: Q, K, V 행렬 준비 (예시: hidden states 사용)
print("\n[Step 1] Query, Key, Value 행렬 준비")
print("-" * 70)
Q = K = V = model_outputs.last_hidden_state.cpu().numpy().squeeze() # (시퀀스길이, 임베딩차원)
d_k = Q.shape[-1] # 헤드당 차원
print(f" Q, K, V 형태: {Q.shape}")
print(f" 시퀀스길이={Q.shape[0]}, 임베딩차원={d_k}")
# 2단계: 유사도 계산
print("\n[Step 2] 유사도 계산: Q @ K^T")
print("-" * 70)
QK = Q @ K.T # (시퀀스, 시퀀스)
print(f" Q @ K^T 형태: {QK.shape}")
print(f" 값 범위: [{QK.min():.2f}, {QK.max():.2f}]")
# 3단계: 스케일링
print("\n[Step 3] 스케일링: (Q @ K^T) / sqrt(d_k)")
print("-" * 70)
scaling_factor = np.sqrt(d_k)
QK_scaled = QK / scaling_factor
print(f" 스케일링 인수: sqrt({d_k}) = {scaling_factor:.2f}")
print(f" 스케일링 후 값 범위: [{QK_scaled.min():.2f}, {QK_scaled.max():.2f}]")
# 4단계: Softmax
print("\n[Step 4] Softmax 정규화")
print("-" * 70)
from scipy.special import softmax
어텐션행렬 = softmax(QK_scaled, axis=-1)
print(f" 어텐션 행렬 형태: {어텐션행렬.shape}")
print(f" 각 행의 합: {어텐션행렬.sum(axis=1)[:3]}...")
print(f" 값 범위: [{어텐션행렬.min():.4f}, {어텐션행렬.max():.4f}]")
# 5단계: 가중합
print("\n[Step 5] 최종 어텐션 출력: Attention @ V")
print("-" * 70)
어텐션출력 = 어텐션행렬 @ V # (시퀀스, 임베딩차원)
print(f" 출력 형태: {어텐션출력.shape}")
print("\n" + "=" * 70)
print("어텐션 계산식: softmax(Q @ K^T / sqrt(d_k)) @ V")
print("=" * 70)
# 시각화
df_attention = pd.DataFrame(어텐션행렬, index=형태소목록, columns=형태소목록).round(3)
display(df_attention)======================================================================
Transformer 어텐션 메커니즘 계산 방식
======================================================================
[Step 1] Query, Key, Value 행렬 준비
----------------------------------------------------------------------
Q, K, V 형태: (14, 768)
시퀀스길이=14, 임베딩차원=768
[Step 2] 유사도 계산: Q @ K^T
----------------------------------------------------------------------
Q @ K^T 형태: (14, 14)
값 범위: [25.81, 339.51]
[Step 3] 스케일링: (Q @ K^T) / sqrt(d_k)
----------------------------------------------------------------------
스케일링 인수: sqrt(768) = 27.71
스케일링 후 값 범위: [0.93, 12.25]
[Step 4] Softmax 정규화
----------------------------------------------------------------------
어텐션 행렬 형태: (14, 14)
각 행의 합: [1. 1. 1.]...
값 범위: [0.0000, 0.9563]
[Step 5] 최종 어텐션 출력: Attention @ V
----------------------------------------------------------------------
출력 형태: (14, 768)
======================================================================
어텐션 계산식: softmax(Q @ K^T / sqrt(d_k)) @ V
======================================================================
Loading...
BERT 어텐션 분석¶
attentions = model_outputs.attentions
임베딩차원 = bert.config.hidden_size
헤드수 = bert.config.num_attention_heads
레이어수 = bert.config.num_hidden_layers
print(f'모델 구조:')
print(f' - 임베딩 차원: {임베딩차원}')
print(f' - 어텐션 헤드 수: {헤드수}')
print(f' - 헤드당 임베딩 차원: {임베딩차원 // 헤드수}')
print(f' - 레이어 수: {레이어수}')
print(f'\n어텐션 텐서')
입력시퀀스길이 = len(정수시퀀스['input_ids'].squeeze())
for i, attn in enumerate(attentions):
assert attn.shape[1:] == (헤드수, 입력시퀀스길이, 입력시퀀스길이)
print(f'(헤드수, 입력시퀀스길이, 입력시퀀스길이) = {(헤드수, 입력시퀀스길이, 입력시퀀스길이)}')모델 구조:
- 임베딩 차원: 768
- 어텐션 헤드 수: 12
- 헤드당 임베딩 차원: 64
- 레이어 수: 12
어텐션 텐서
(헤드수, 입력시퀀스길이, 입력시퀀스길이) = (12, 14, 14)
어텐션_계층번호 = 0
print(f"어텐션 텐서 크기: {attentions[어텐션_계층번호].shape}")
# 첫 번째 레이어, 첫 번째 헤드 선택
attn_layer0_head0 = attentions[어텐션_계층번호][0, 0].cpu().numpy() # (시퀀스길이, 시퀀스길이)
assert np.allclose(attn_layer0_head0.sum(axis=1), 1.0)
# 테이블로 확인
df_attn_head0 = pd.DataFrame(attn_layer0_head0, index=형태소목록, columns=형태소목록).round(3)
display(df_attn_head0)1층 어텐션 텐서 크기: torch.Size([1, 12, 14, 14])
Loading...
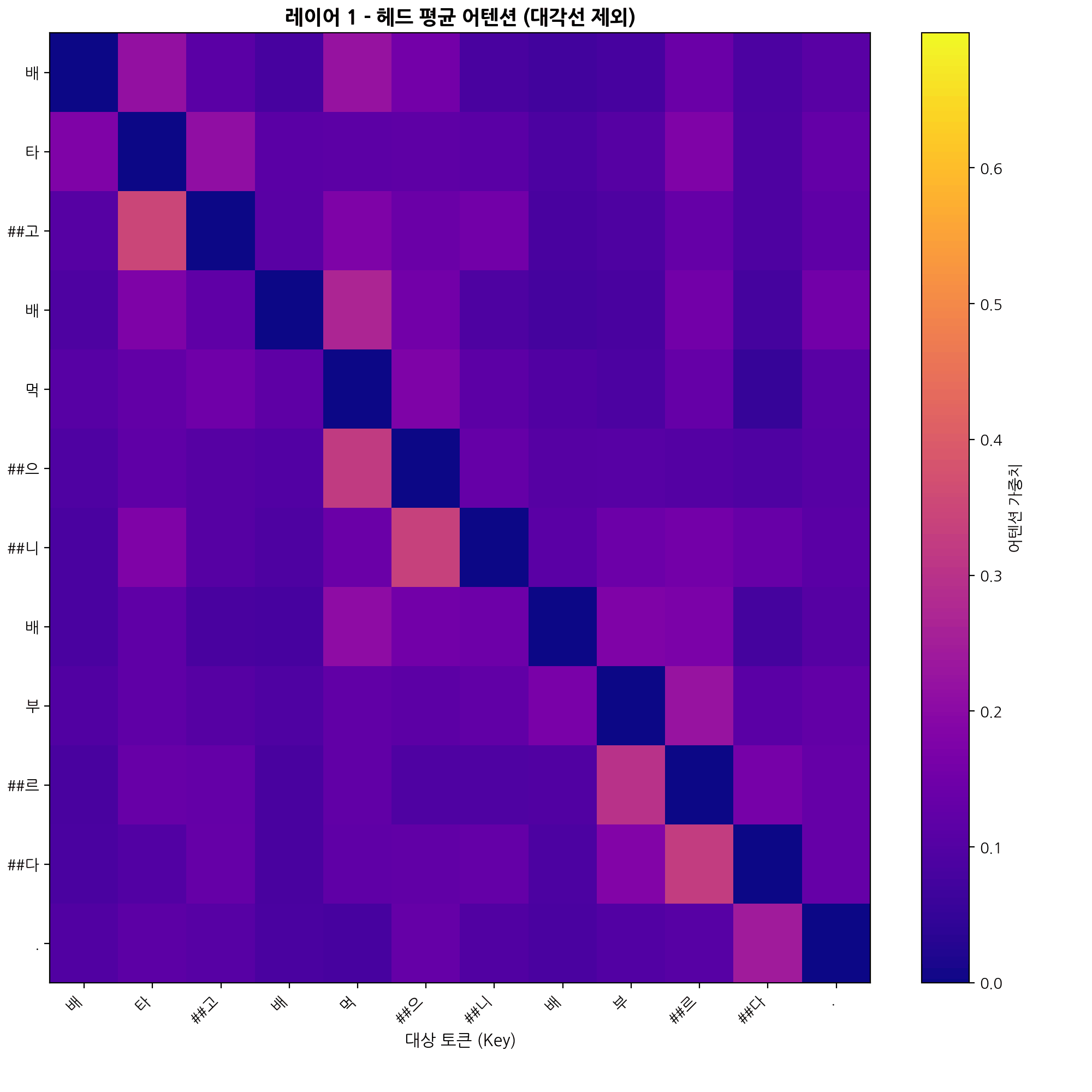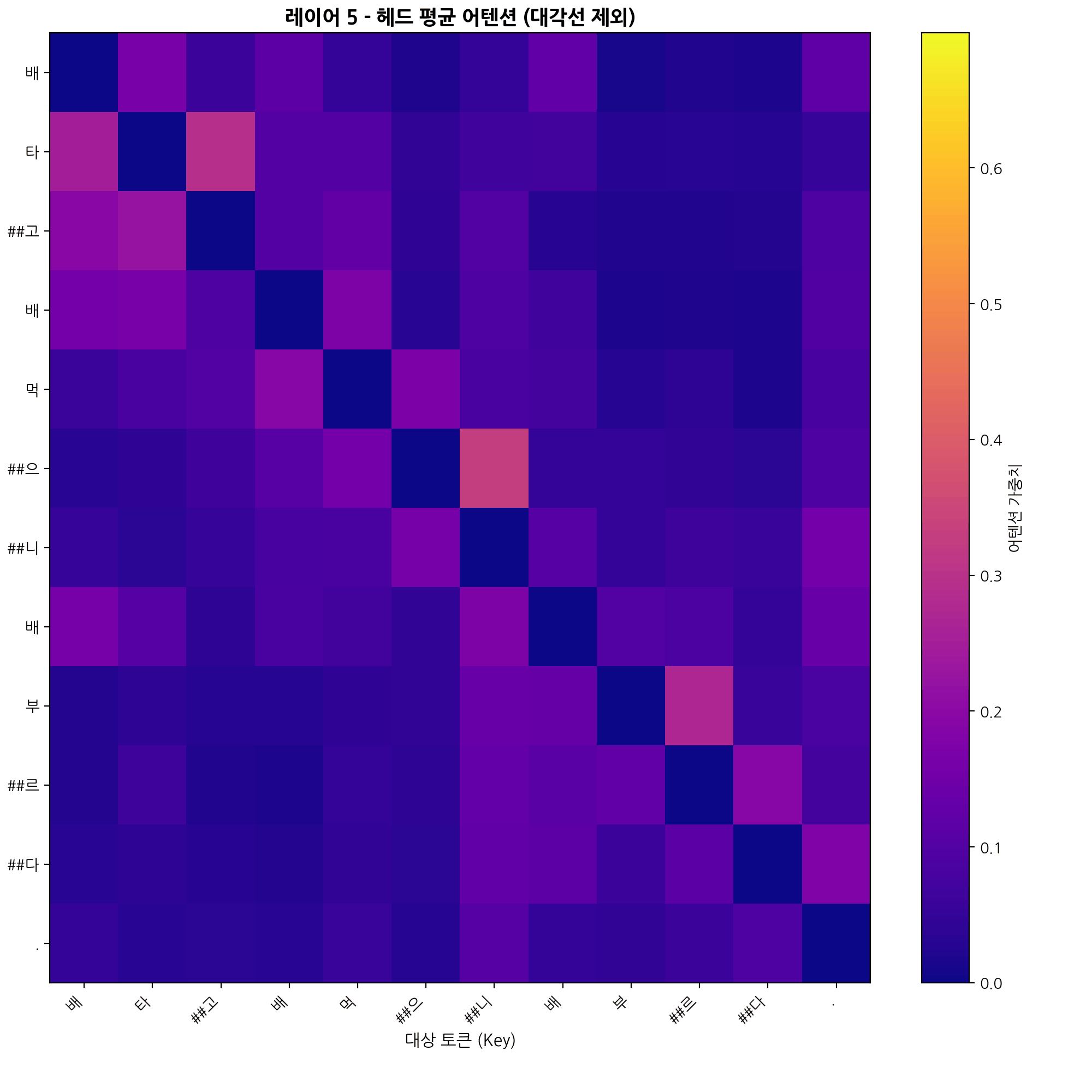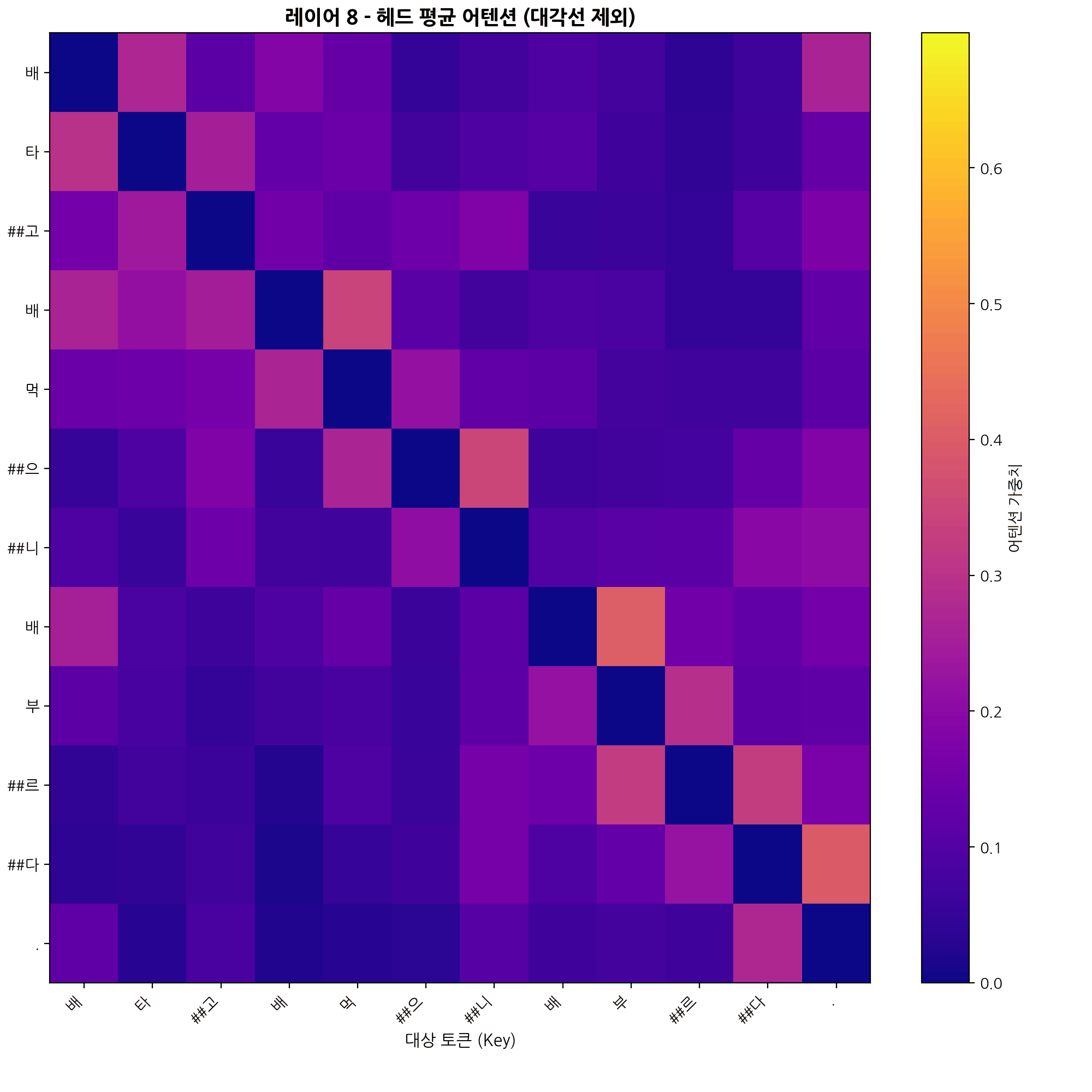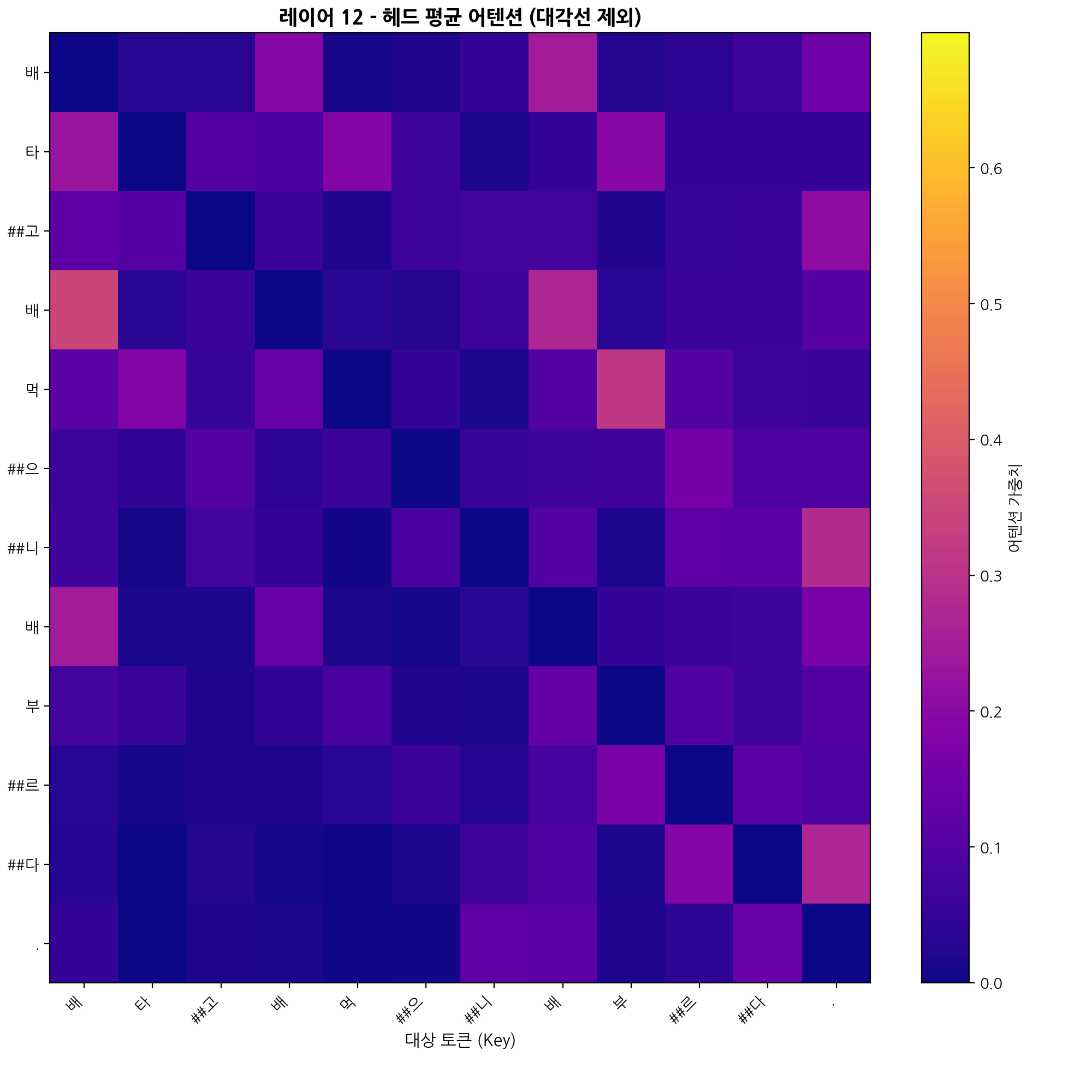
# 헤드와 계층 평균
계층별_어텐션평균 = [attn_tensor[0].cpu().numpy().mean(axis=0) for attn_tensor in attentions]
어텐션평균 = np.mean(계층별_어텐션평균, axis=0)
assert np.allclose(어텐션평균.sum(axis=1), 1.0)
# CLS, SEP 토큰 제외
어텐션평균 = 어텐션평균[1:-1, 1:-1]
print(f"레이어 {어텐션_계층번호+1}의 {헤드수}개 헤드 평균 어텐션")
print(f"형태: {어텐션평균.shape}\n")
# 자기 자신의 어텐션을 0으로 마스킹
attn_avg_masked = 어텐션평균.copy()
np.fill_diagonal(attn_avg_masked, 0)
# softmax 재계산
attn_avg_masked = attn_avg_masked / attn_avg_masked.sum(axis=1, keepdims=True)
# 히트맵 시각화
tokens = 형태소목록[1:-1] # CLS, SEP 제외
fig, ax = plt.subplots(figsize=(8, 7))
im = ax.imshow(attn_avg_masked, cmap='plasma', aspect='auto')
ax.set_xticks(range(len(tokens)))
ax.set_yticks(range(len(tokens)))
ax.set_xticklabels(tokens, rotation=45, ha='right')
ax.set_yticklabels(tokens)
ax.set_xlabel('대상 토큰 (Key)', fontsize=12)
ax.set_ylabel('소스 토큰 (Query)', fontsize=12)
ax.set_title(f'어텐션 (전체 계층/헤드 평균)', fontsize=13)
# 행별 최고값 강조
for i in range(len(tokens)):
j = np.argmax(attn_avg_masked[i])
ax.text(j, i, f"{attn_avg_masked[i, j]:.2f}", color='black', fontsize=9,
ha='center', va='center', fontweight='bold')
plt.colorbar(im, ax=ax, label='어텐션 가중치')
plt.tight_layout()
plt.show()
print("\n각 토큰이 주목하는 토큰 (자기 자신 제외):")
for i, token in enumerate(tokens):
# 최고값 선택
idx = np.argmax(attn_avg_masked[i])
weight = attn_avg_masked[i, idx]
print(f" {token:8} → {tokens[idx]:8} ({weight:.3f})")레이어 1의 12개 헤드 평균 어텐션
형태: (12, 12)
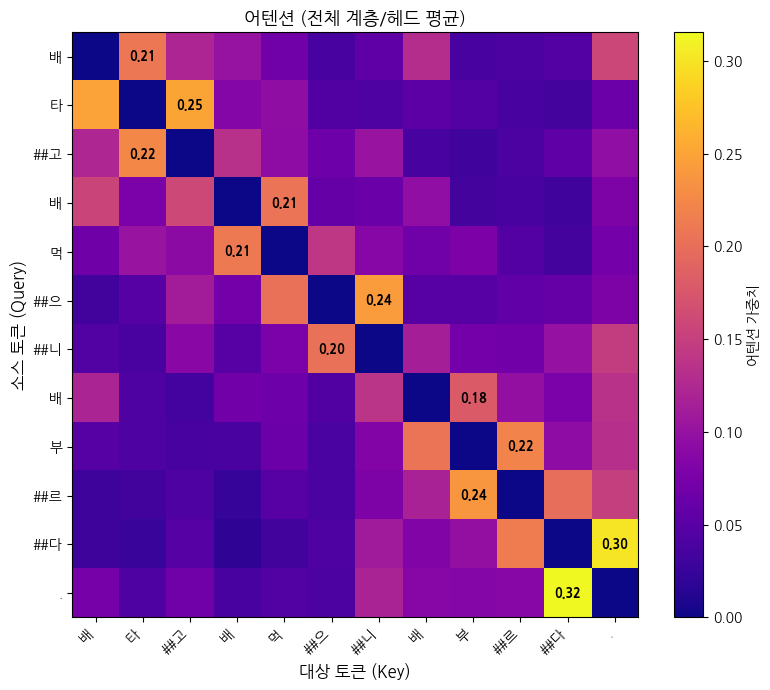
각 토큰이 주목하는 토큰 (자기 자신 제외):
배 → 타 (0.209)
타 → ##고 (0.251)
##고 → 타 (0.224)
배 → 먹 (0.206)
먹 → 배 (0.211)
##으 → ##니 (0.244)
##니 → ##으 (0.202)
배 → 부 (0.179)
부 → ##르 (0.221)
##르 → 부 (0.238)
##다 → . (0.302)
. → ##다 (0.315)
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/abs/1810.04805